

目次 ▼
noindexとnofollowを混同してない?
WEBページのmetaタグに記述する「noindex(ノーインデックス)」「nofollow(ノーフォロー)」「noarchive(ノーアーカイブ)」の意味や違いはわかりますか。
たとえば、Wordpressには、記事の編集画面でWEBページに対して「nofollow」や「noindex」のチェック項目がありますね。また、「nofollow」や「noindex」を管理するプラグインもあります。
「nofollow」と「noindex」を混同して認識したり、よくわからずに使っている人もいますが、これらは使い分けが必要なものです。
間違っても、「なんかチェックがあるから入れとこー。」という感覚で操作するものではありません。
- noindex、nofollow、noarchiveの意味と使い方
- noindex、nofollowとSEOの関係
それでは早速見ていきましょう。
noindex(ノーインデックス)とは
「noindex」とは、あるWEBページを検索結果に表示したくない場合に、ヘッダーのmetaタグに記載するものです。
WEBページは、検索エンジンにインデックスされると検索対象になりますが、「noindex」が記載されたWEBページはインデックス自体を拒否します。ただし、クローラーによる巡回は行われるため、発リンクをたどることはできます。
インデックスやクローラーの説明は、以下を参考にしてください。
noindexの書き方
「noindex」は、ヘッダー(head内)のmetaタグに、以下のように記述します。
<meta name="robots" content="noindex"/>
noindexの使い方・使う理由
「noindex」を使う理由は、WEBサイト内にある重複コンテンツや低品質コンテンツを解消するためです。重複コンテンツや低品質コンテンツをGoogleにインデックスさせないことで、WEBサイト全体の質を上げる効果があります。
ただし、GoogleのJohn Mueller(ジョン・ミューラー)氏は、重複コンテンツには「noindex」ではなく、「canonical(カノニカル)」を使うことを推奨しています。
「canonical」とは、あるWEBページと同一内容のコンテツがあることをGoogleに伝えたい場合に、ヘッダー内に以下のように記述するものです。「canonical」を使うと、タグ内に記述したWEBページの方が優先されます。こちらは、また別途お話します。
<link rel="canonical" href="http://wakarukoto.com/?p=xxxxxxxxx">
また、単純に質が低いコンテンツは、「noindex」を使うのではなく、リライトをして質を高めた方が効果的です。一部の質が低いコンテンツが残っていても、とくにWEBサイト全体に影響は与えません。
低品質コンテンツがわずかに存在していても検索では問題にならない。検索トラフィックがないことは価値がないことを意味しない | 海外SEO情報ブログ
nofollow(ノーフォロー)とは
「nofollow」とは、あるWEBページの発リンクをクローラーにたどらせたくない場合(クローリングの拒否)に、ヘッダーのmetaタグに記載するものです。
nofollowの書き方
「nofollow」は、ヘッダー(head内)のmetaタグに、以下のように記述します。
<meta name="robots" content="nofollow"/>
WEBページのすべてのリンクではなく、ある発リンクのみクローリング拒否をしたい場合は、そのリンクタグ内に以下のように記述してもOKです。
<a href="https://○○○○○.com/" rel="nofollow">テストサイト</a>
nofollowの使い方・使う理由
「nofollow」を使う理由は、Googleのガイドラインに記載されています。
特定のリンクに対して rel=”nofollow” を使用する – Search Console ヘルプ
信頼できないコンテンツの影響を除外するため
信頼できないコンテンツ、詐欺やスパムなど犯罪性があるサイトをリンクする場合、「nofollow」を使えば、被リンク先から攻撃を受けたり、低品質な被リンクを避けられます。
また、発リンクページが持つページランク(PageRank)を被リンクページに渡して、検索エンジンの評価に影響を与えることもありません。
有料リンクや広告へのリンクの影響を除外するため
Googleでは、有料サイトへのリンクも順位付けに影響することがあります。そのため、たとえば設置した広告(バナーなど)に「nofollow」を使うと、影響を受けなくなります。
クロールの優先順位を上げるため
Googleのクローラーは、パスワードが設定されたページを巡回できません。そのため、「ログイン」に対するリンクを「nofollow」設定することで、他のページを優先的にクロールさせられます。
noarchive(ノーアーカイブ)とは
「noarchive」とは、あるWEBページのキャッシュを作りたくない場合に、ヘッダーのmetaタグに記載するものです。
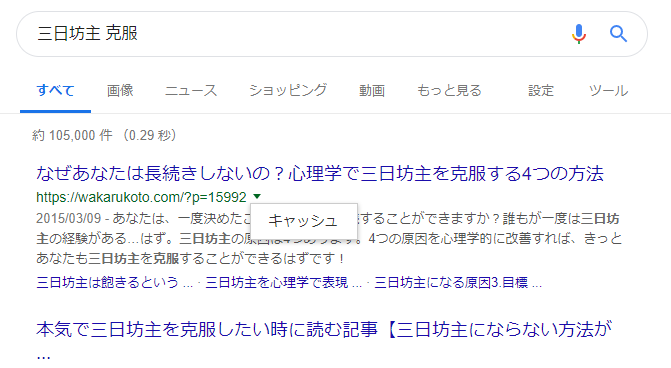
Googleは、インデックスしたWEBページの情報をからキャッシュページを作ります。キャッシュページは、検索結果のURL横の▼から表示できます。このキャッシュ作成を拒否するのが「noarchive」です。
noarchiveの書き方
「noarchive」は、ヘッダー(head内)のmetaタグに、以下のように記述します。
<meta name="robots" content="noarchive">
noarchiveの使い方・使う理由
「noarchive」を使う理由は、キャッシュページの表示がデメリットになる場合です。
たとえば、頻繁に価格を変更するECサイトの商品ページ、個人情報など機密情報が記載されたWEBページなどのキャッシュを削除したり、最初からキャッシュさせないために使います。
noindex・nofollowを使うとSEO対策になる?
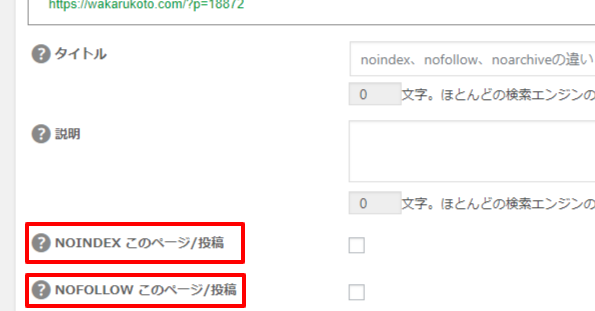
ちなみに「noindex」や「nofollow」は、Wordpressプラグインの「All in One SEO」では、以下のように簡単にチェックできます。
ただ、現在は「noindex」「nofollow」「noarchive」は、あまり使う機会はありません。「noindex」や「nofollow」をSEO対策の1つとして使った方が良いというのは、すでに古い考え方です。
前述した通り、重複コンテンツの解消には「noindex」より「canonical」を使った方がGoogleに明確に意図を伝えられますし、そもそも質が低いコンテンツはリライトした方が良いです。
また、「nofollow」を使ってリンクジュースを操作するページランクスカルプティングも、随分前に意味のない行為になってしまいました。
というわけで、「noindex」「nofollow」「noarchive」は使う場面が限られますが、正しい使い方をして、より良いサイトづくりに役立ててください。
nofollow|発リンクのクローリングを拒否する
noarchive|ページのキャッシュ作成を拒否する














